Design data storage solutions
- By Ashish Agrawal, Avinash Bhavsar, Gurvinder Singh, Mohammad Sabir Sopariwala
- 6/26/2023
- Skill 2.1: Design a data storage solution for relational data
- Skill 2.2: Design data integration
In this sample chapter from Exam Ref AZ-305 Designing Microsoft Azure Infrastructure Solutions explore the critical concepts of designing data storage solutions and data integration on the Microsoft Azure cloud platform. Cover topics such as designing solutions for relational and non-relational data, database service tier sizing, scalability, encryption, sharding, read scale-out, and elastic pools.
In today’s information era, data is growing rapidly and exponentially. The generation of this vast amount of data opens a door for organizations to use it effectively to make business decisions.
Like a wide variety of IoT devices and social networking sites, database applications generate massive amounts of data. Handling this volume of data with a traditional relational database approach can be challenging and inefficient. The heterogeneity and complexity of the data—also known as big data—emitted by numerous connected devices also make it challenging to manage traditional database storage solutions.
Because the AZ-305 exam is an expert-level exam, you must thoroughly understand Microsoft’s data storage services, use your architectural thinking, and design a precise data storage solution. In this chapter, you will learn the critical concepts of designing data storage solutions and data integration on the Microsoft Azure cloud platform.
Skills covered in this chapter:
Skill 2.1: Design a data storage solution for relational data
Skill 2.2: Design data integration
Skill 2.3: Recommend a data storage solution
Skill 2.4: Design a data storage solution for nonrelational data
Skill 2.1: Design a data storage solution for relational data
A database is the foundation of any application. An accurate database design provides consistent data, high performance, scalability, less management, and, ultimately, user satisfaction. A modern database must address new challenges, such as massive amounts of data, diverse data sources, multiregion deployment, and so on. The Azure cloud platform helps overcome these challenges by providing sets of Azure database services.
In this skill, you will examine the solutions for relational databases’ service tiers, scalability, and encryption in Azure.
Recommend database service tier sizing
The selection of service tiers for the Azure platform’s database depends on the database type and whether it is a single database, an elastic pool, or a managed instance. Also, in a single instance or an elastic pool, the selection of service tiers depends on the purchasing model—virtual core (vCore)–based or database transaction unit (DTU)–based. Let’s start with database types.
Following are the database service tiers based on the purchasing model:
DTU-based purchasing model:
Basic
Standard
Premium
vCore-based purchasing model:
General purpose
Business critical
Hyperscale
DTU-based purchasing model
Let’s look at the DTU-based purchasing model. DTU stands for database transaction unit, and it blends CPU, memory, and I/O usage. The more DTUs, the more powerful the database. This option is suitable for customers who would like to use a simple preconfigured resource bundle.
When migrating a database from on-premises to Azure, you can get the current CPU, disk read/write, log bytes, and flushed/sec information from the current on-premises server and calculate the required DTU value on the target Azure SQL Database.
Table 2-1 lists the characteristics of DTU-based service tiers.
TABLE 2-1 DTU-based service tiers
|
Basic |
Standard |
Premium |
|---|---|---|---|
MAXIMUM STORAGE SIZE |
2 GB |
1 TB |
4 TB |
CPU |
Low |
Low, medium, high |
Medium, high |
MAXIMUM DTUs |
5 |
3,000 |
4,000 |
I/O THROUGHPUT |
1–5 IOPS per DTU |
1–5 IOPS per DTU |
25 IOPS per DTU |
UPTIME SLA |
99.99 percent |
99.99 percent |
99.99 percent |
I/O LATENCY |
Read: 5 ms Write: 10 ms |
Read: 5 ms Write: 10 ms |
Read/write: 2 ms |
MAXIMUM BACKUP RETENTION |
7 days |
35 days |
35 days |
COLUMNSTORE INDEXING |
N/A |
S3 and above |
Supported |
IN-MEMORY OLTP |
N/A |
N/A |
Supported |
ACTIVE GEO-REPLICATION |
Yes |
Yes |
Yes |
READ SCALE-OUT |
No |
No |
Yes |
vCore-based purchasing model
In the vCore purchasing model, you have the flexibility to independently pick compute, memory, and storage based on your workload needs. So with this flexibility, you can easily map the on-premises database’s vCore, memory, and storage, and choose the matching Azure database tier.
The vCore-based purchasing model offers Azure Hybrid Benefit (AHB), which allows you to use existing licenses for a discounted rate on Azure SQL Database and Azure SQL Managed Instance. AHB enables you to save 30 percent or more on your SQL Database and SQL Managed Instance by using your existing SQL Server licenses with Software Assurance.
Table 2-2 lists the characteristics of vCore-based service tiers.
TABLE 2-2 vCore-based service tiers
|
Database |
General Purpose |
Business Critical |
Hyperscale |
|---|---|---|---|---|
DATABASE SIZE |
SQL Database |
5 GB–4 TB |
5 GB–4 TB |
Up to 100 TB |
SQL Managed Instance |
32 GB–8 TB |
32 GB–4 TB |
N/A |
|
COMPUTE SIZE |
SQL Database |
1 to 80 vCores |
1 to 80 vCores |
1 to 80 vCores |
SQL Managed Instance |
4, 8, 16, 24, 32, 40, 64, and 80 vCores |
4, 8, 16, 24, 32, 40, 64, and 80 vCores |
N/A |
|
AVAILABILITY |
All |
99.99 percent |
99.99 percent; 99.995 percent with zone redundant single database |
99.95 percent with one secondary replica; 99.99 percent with more replicas |
STORAGE TYPE |
All |
Premium remote storage (per instance) |
Super-fast local SSD storage (per instance) |
De-coupled storage with local SSD cache (per instance) |
BACKUP |
All |
RA-GRS, 7–35 days (7 days by default) |
RA-GRS, 7–35 days (7 days by default) |
RA-GRS, 7 days, constant time, point-in-time recovery (PITR) |
IN-MEMORY OLTP |
All |
N/A |
Available |
N/A |
READ SCALE-OUT |
All |
No |
Yes |
No |
Recommend a solution for database scalability
One of the objectives of moving an application to the cloud is to support a growing load. An application should be able to increase resources (compute, storage, and so on) to sustain the on-demand load and decrease resources when demand goes down. This flexibility is called elastic scaling. With elastic scaling, you can use optimal resources and pay only for what you use.
Following are two methods of scaling:
Vertical scaling With this method, the capacity of the same resource is changed to meet the requirement. For example, you can increase (scale up) VM size from Standard_D2_v2 to Standard_D3_v2 and similarly decrease (scale down) VM size from Standard_D3_v2 to Standard_D2_v2. When you change the size of the same VM, a restart is required, which means the application deployed on the VM is unavailable until the VM restarts and comes back online. Therefore, this method is generally not automated. This method is also called scale-up and scale-down.
Horizontal scaling In this method, capacity is increased or decreased by adding or removing instances of resources. For example, you can add one more VM to the load balancer set to meet the increasing load on the application. Similarly, you can remove an existing VM from the load balancer set when there is less load on the application. During this scaling, the application does not become unavailable or experience down-time. Therefore, this is the preferred method for autoscaling. All Azure services that support autoscaling are based on this method only.
Autoscaling is a feature of Azure services that automatically adds or removes resources based on the actual load on the services. Autoscaling eliminates the overhead of the operation team to monitor utilization and adjust resources.
The following sections examine the options available to scale SQL databases.
Azure SQL Database Serverless
Serverless is a vertical scaling option that has been introduced as a new compute tier. This tier automatically scales up or scales down the database’s compute based on the actual load. You can specify the minimum and maximum vCore range that the database can use. Memory and I/O limits are proportional to the specified vCore range. The cost of the Serverless tier is the sum of compute and storage cost. The compute cost is calculated based on the number of vCores used per second. The Serverless tier is available under the General Purpose tier in the vCore purchasing model.
Another exciting feature of the Serverless tier is autopause. When the database is inactive, the Serverless compute tier pauses the database automatically, and it resumes the database when activity returns. There is no compute cost when the database is in the paused state, but you do pay for storage costs.
Autopause delay is the time duration for which the database must be in an inactive state before it is automatically paused. The minimum autopause delay is one hour. Figure 2-1 depicts the minimum and maximum vCore configuration, actual CPU utilization, autopause delay period, and autopause.
){kind=link}
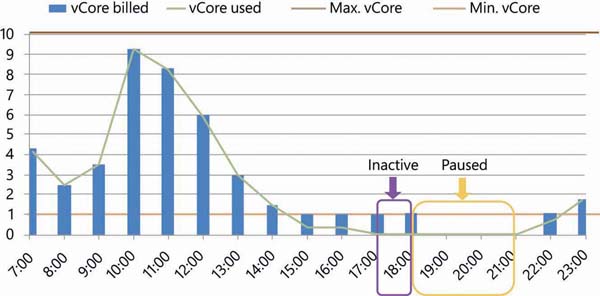
FIGURE 2-1 Serverless database configuration and its vCore utilization
In this example, between 7:00 to 14:00 hours, the number of vCores used is more than 1. During this period, vCores used and vCores billed are the same. From 15:00 to 18:00 hours, the vCore used is below 1. However, even though it is below 1 vCore, it will be billed as 1 vCore because that is the minimum vCore configuration. From 17:00 to 18:00 hours, vCore utilization is 0 because of database inactivity. The Azure SQL Database Serverless tier monitors this for one hour, which is called autopause delay. After one hour, the database is paused at 19:00 hours. At 21:00 hours, SQL Database resumes responding to activity.
Following are scenarios in which you would use SQL Database Serverless:
A new single database (either migrated from on-premises or freshly deployed on Azure) in which vCore and memory requirements are unknown
A single database with an unpredictable usage pattern, with an inactive period and below-average vCore utilization
Sharding
Sharding is an architecture pattern in which a large set of data is distributed into multiple identically structured databases deployed into separate compute nodes called shards. Data is distributed into shards based on a list of values or ranges of values called sharding keys. This metadata information (mapping) about data distribution is stored in a separate database called a shard map manager.
List-based mapping is called list mapping, whereas range-based mapping is called range mapping. The shard map manager database is used by the application to identify the correct database (shard) using the sharding key to perform database operations.
This sharding method is most suitable for software as a service (SaaS) applications. SaaS application developers created sharding patterns to support a large volume of data and a large user base. Customers of the SaaS application are referred to as tenants. If all the data pertaining to one customer is stored in a single database, then it is called a single-tenant model. For this model, the shard map manager stores the global mapping information using a list of tenant IDs. This mapping is called list mapping. Figure 2-2 depicts the single-tenant model.
){kind=link}
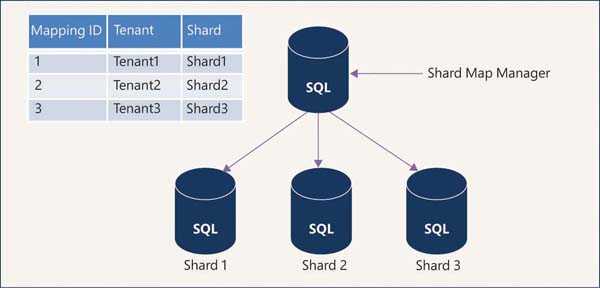
FIGURE 2-2 Single-tenant model
When the application needs a small amount of data for one tenant, then data from multiple tenants is stored in one database using a multitenant model. This model uses range mapping in which the shard map manager keeps the mapping between ranges of the tenant ID and the shard. Figure 2-3 shows the multitenant model.
){kind=link}
The Elastic Database tools are a set of libraries and tools that create and manage shards:
Elastic database client library This is a .NET and Java library that is used to create and maintain sharded databases.
Elastic database split-merge tool This tool is useful for moving data between sharded databases.
Elastic database jobs This tool is used for schema changes, credential management, reference data updates, and telemetry collection.
Elastic database query This tool allows you to run a transact-SQL query that spans multiple databases.
Elastic transactions This tool allows you to run transactions that span multiple databases.
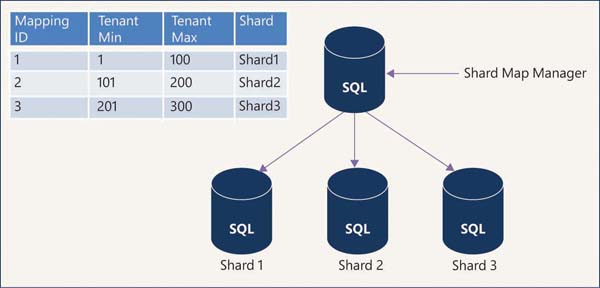
FIGURE 2-3 Multitenant model
Following are some scenarios in which you would use sharding:
You need to store customers’ data in different geographies for geopolitical, performance, or compliance reasons.
The volume of data is enormous and cannot fit into a single database.
The transaction throughput requirement is very high and cannot be accommodated by a single database.
Certain customers’ data must be isolated from other customers’ data.
Sharding provides high availability, more bandwidth, more throughput, and faster query response and processing. It also helps to mitigate the outage impact in the following scenarios:
databases are stored in different geographies and one of the locations is experiencing an outage.
All databases are stored in a single region and one of the databases is experiencing an issue/outage.
In the preceding scenarios, only one customer (tenant) will be affected if you have chosen the single-tenant model, and only a few customers will be affected if you have chosen a multitenant model. Thus, the application’s overall impact will be less than the non-sharding application, in which the whole application will crash.
While sharding offers many benefits, it also adds complexity, with creating and managing shards and moving data between shards. You must carefully design your sharding architecture and choose the right sharding keys, which are discussed in the following sections.
Read Scale-Out
There might be some scenarios in which the latest data is not immediately available in the read-only replica because of latency issues. You must consider this small latency when selecting read-only replicas for your application. You can use sys.dm_database_replica_states dynamic management views (DMVs) to monitor the replication status and synchronization statistics. When the client/application tries to connect to the database, the gateway internally checks connections strings for the ApplicationIntent parameter. If the value of the parameter is ReadOnly, then it routes the request to a read-only replica. If the value of the parameter is ReadWrite, then it routes that request to a read-write replica. ReadWrite is the default value of the ApplicationIntent parameter.
Following are some scenarios when you would use read scale-out:
An analytics workload that only reads data for analysis purposes
A reporting application that only reads data and generates various reports
An integration system that only reads data
Elastic Pool
An elastic pool is a collection of databases deployed on a single server that shares resources allocated to the pool. The capacity of the pool is fixed and does not change automatically. So within a fixed capacity of the pool, databases scale automatically within a minimum and maximum capacity defined by the Per Database setting on the Configure blade of the elastic pool settings in Azure Portal.
The elastic pool can use either DTU-based or vCore-based models. In a DTU-based model, databases can scale between a minimum and maximum DTU that is specified by the Per Database setting. Similarly, in a vCore-based model, a database can scale between a minimum and maximum vCore that is specified by the Per Database setting.
The size of the elastic pool can be changed with minimal downtime. A database can be added or removed from an elastic pool. The cost of the elastic pool depends on the size of the pool and not on the individual databases allocated in the pool. So more databases in the pool means more cost savings.
Following are some scenarios in which to use an elastic pool:
For an application or a group of applications with a large number of databases having low utilization and few, infrequent spikes
For a SaaS application that requires multiple databases with low to medium utilization
Table 2-3 provides a quick comparison of scaling methods.
TABLE 2-3 Scaling methods
|
Azure SQL Data- base Serverless |
Sharding |
Read Scale-Out |
Elastic Pool |
|---|---|---|---|---|
SCALING METHOD |
Vertical |
Horizontal |
Horizontal |
Vertical |
AUTOSCALING |
Yes |
No |
No |
Autoscaling within the minimum and maximum defined settings |
EASE OF IMPLEMENTATION |
Yes |
No |
Yes |
Yes |
MANAGEABILITY |
Fully managed |
Customer managed |
Fully managed |
Fully managed |
AUTOPAUSE TO SAVE COMPUTE COST |
Yes |
No |
No |
No |
READ-ONLY VERSUS READ-WRITE REPLICA |
Read-write |
Read-write |
Read-only |
Read-write |
Recommend a solution for encrypting data at rest, data in transmission, and data in use
Encryption is the process of scrambling or encoding data so that only authorized users can decrypt and read that data. Encryption is required when data is stored, in motion, or in use. Effective encryption is the key to securing an organization’s confidential data at rest, transit, and use. Encryption adds an additional layer of data protection. Even if unauthorized users gain access to encrypted data storage, they can’t read data from that encrypted storage. In this skill, you learn how to protect the data storage on Azure platforms using encryption for data at rest, in transit, and in use.
Symmetric and asymmetric key encryption
There are two main types of encryption:
Symmetric With symmetric encryption, the same key is used to encrypt and decrypt data.
Asymmetric This encryption uses two keys—a public key and a private key. The public key is used to encrypt data, which is shared with everyone, whereas the private key is used to decrypt data, and is kept securely and shared with only intended users.
Encrypting data at rest
Encryption at rest is the data protection method for data stored in persistent storage on physical media. Microsoft uses symmetric key encryption for data at rest. Encryption at rest is mandatory for an organization to be compliant with HIPAA, PCI, and FedRAMP standards.
Microsoft uses key hierarchy models for implementing data at rest. It has two types of keys:
Data encryption key (DEK) This key is used to encrypt and decrypt actual data.
Key encryption key (KEK) This key is used to encrypt the data encryption key.
These keys must be secured. It is recommended that you store them in Azure Key Vault. You can use Azure Active Directory to manage and control access to the keys stored in Azure Key Vault. Encryption can be done at the client side or server side, based on your needs.
The encryption models shown in the following sections provide more details about the implementation of encryption:
Client-side encryption model
Server-side encryption model
Client-side encryption model
In this model, encryption is done at the client side before storing data in the Azure services. You must handle the encryption, decryption, and key management (such as key rotation) in the client application.
Server-side encryption model
In this model, encryption and decryption are performed by the Azure service, and you or Microsoft can manage the encryption keys. The server-side encryption model is classified into the following three types:
Using service-managed keys The Azure service performs encryption, decryption, and key management.
Using customer-managed keys in Azure Key Vault You must manage keys using Azure Key Vault. The Azure service performs encryption and decryption using the Key Vault.
Using customer-managed keys on customer-controlled hardware The Azure service performs encryption and decryption, and you must manage keys using your hardware.
Microsoft’s Azure platform supports encryption at rest for platform as a service (PaaS), infrastructure as a service (IaaS), and software as a service (SaaS).
Encrypting data in transmission
Encrypting data in transmission is the data protection method for data that is actively moving from one component to another. It could be moving across the internet or through a private network.
Microsoft offers the following features for encrypting data in transmission:
Transport Layer Security (TLS) TLS is a cryptographic protocol that provides data integrity, privacy, and authentication during communication between two components over a network. Microsoft protects data using TLS when data is traveling between cloud services and client systems.
Azure App Services With Azure App Services, you can enforce an encrypted connection by setting the HTTPS value to ON. Once enabled, any HTTP connection to your Azure App Service is redirected to an HTTPS URL.
Azure SQL Database and SQL Managed Instance Both the Azure SQL Database and SQL Managed Instance features always enforce an SSL/TLS connection, irrespective of the encrypt or TrustServerCertificate setting in the connection string.
Azure Storage Azure Storage supports both HTTP and HTTPS protocols. You can enforce HTTPS by enabling the Secure Transfer Required property. When you do, any call to Azure Storage using the HTTP protocol is rejected. Similarly, any SMB connection without encryption to the Azure file share will also be rejected. By default, this property is enabled when you provision a new storage account.
Azure virtual machine The remote desktop protocol (RDP) connection to Azure VMs uses TLS to protect data in transit. Also, data in transit is encrypted when you connect to a Linux VM using the Secure Shell (SSH) protocol.
VPN connection A site-to-site VPN connection uses IPsec, while a point-to-site VPN connection uses the secure socket tunneling (SSTP) protocol to encrypt the communication.
Data-link layer encryption Microsoft applies the IEEE 802.1AE MAC security standard for data in transit between datacenters. This encryption method is also known as MACsec. This encryption is enabled for all the traffic within a region or between regions.
Encrypting data in use
Data in use describes data that is actively being used by the user or system for processing. This data is stored in nonpersistent storage such as RAM.
Always Encrypted is a client-side encryption technique that protects sensitive data, such as Social Security numbers (SSN), credit card numbers, and personally identifiable information (PII) stored in SQL Server databases and SQL Azure databases. A database driver inside the client application encrypts data before storing it in the database, and it decrypts encrypted data retrieved from the database.
Because encryption is happening at the client side, the keys used to encrypt data are never revealed to the database. Thus, by using this feature, even a database administrator or cloud database operator who manages the database server and who has full control of the database cannot see original decrypted data.
The Always Encrypted feature uses the following keys:
Column encryption keys These keys are used to encrypt data before storing it in the database.
Column master keys These keys are encrypted by using column master keys.
Column encryption keys are stored in the database in encrypted form, and column master keys are stored outside the database—for example, in a local key management system or Azure Key Vault.
This feature encrypts data at rest, in transit, and in use. Hence, it is called Always Encrypted. However, transparent data encryption (TDE) is the recommended option for encrypting data at rest.